2022年9月25日
薙刀式というカナ配列を練習し始めて、カナについてあれこれ思いを巡らすことが増えました。
薙刀式には記憶負担が少ない「清濁拗外来音同置」などの特徴がありますが、1 薙刀式でタイピングの練習をしていると、「ある」「する」「ない」といった言葉が右手(人差し指と中指)にあったり、いわゆる「てにをは」が左手(中指)にあったりすることを体感します。
「カナにはそれぞれ(いくつかの)役割がある」ということを意識せずにはいられません。
そして、それは各個人の言語感覚(と身体感覚)だけに依存しない、ある程度普遍的なこともあるんじゃないかとも思いました。
日本語の文章に使われるカナのうち、頻度が高いものは「い」であることが知られています。このため、カナ配列ではホームポジションに「い」が置かれているものが多いようです。
ではいったい、この「い」はどんな役割で、どのくらい使われているのでしょうか。
たとえば「ナイロンがない」という文では、ただ単純に「い」をカウントするとき、どちらの「い」も平等に扱われます。しかし「ナイロン」と「〜がない」では「い」の役割が異なります。「〜がない」のような使い方の「い」は、どのくらいの頻度で出てくるのでしょう。
満足のいく答えを得るのは簡単ではないですが、(多くの人が考えるであろう)ひとつの切り口は「品詞」だと考えました。
品詞情報のついたカナの頻度ってどうなるんだろう? とインターネット上で関連情報を探してみたのですが、文章中にあらわれる単語の頻出度や品詞の頻出度などを求めるものはあったものの、品詞別のカナの頻出度を求めているものが見つけられなかったため、じゃあちょっとやってみるか、となったわけです。2
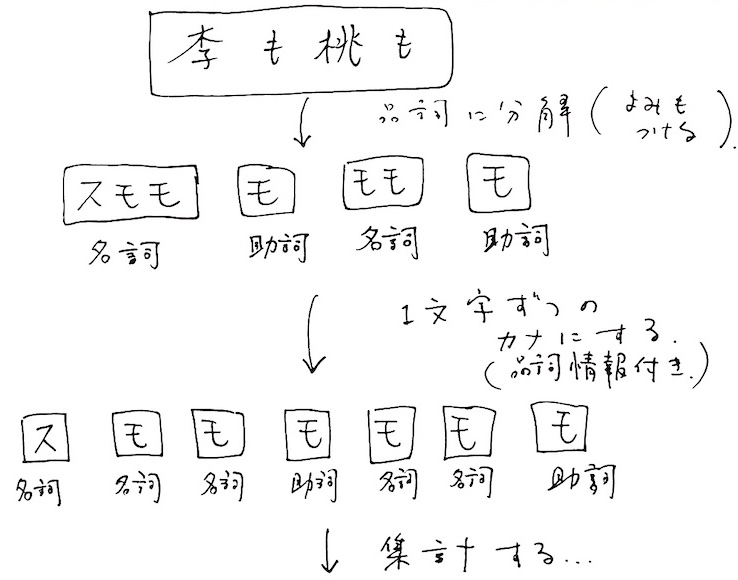
やりたいことのイメージはこんな感じです。
つまり、
ということです。単に「カナに品詞情報を付ける」という過程が加わったカナの統計ですね。
一番難しそうな形態素解析の部分は形態素解析エンジンにまかせます。集計処理はRという言語を使います。
世の中にはいろいろな形態素解析エンジンがありますが、MeCab を使います。自分の場合(macOS 12.6)は、Homebrew からインストールしました。なお、MeCabとは別に、解析のための辞書を別途インストールする必要があります。
形態素解析をした後、漢字によみがなを振る作業が必要になると思っていたのですが、形態素解析の結果によみがなが含まれているため、その結果を利用すればいいことに気づきました。
正しく読めない漢字も少なからずありますが、そういう難しそうな漢字はあんまり影響なさそうなので今回は気にしないことにします。
MeCabのデフォルトの出力は、一見カンマ区切りのデータのように見えますが、タブとカンマの混じったテキストデータです。割とこういう部分がつまづきの元になります。必要な部分だけのタブ区切りデータにしたいので、出力フォーマットをカスタマイズします。
出力フォーマットの詳細は公式サイトに書いてあります。
また、データの最後についてくる”EOS”(End Of String)という文字列も、複数の行からなるテキストを解析するときには必要がないので、表示しないようにオプションで設定をします。
たとえば「新配列を設計してきた先人たちがいる。」という文をオプション付きでMeCabに食べさせてみたいときは、次のようにします。
echo "新配列を設計してきた先人たちがいる。" | mecab -F "%f[7]\t%f[0]\t%f[1]\n" -E ""このときの咀嚼結果は次の通りです。
シン 接頭詞 名詞接続
ハイレツ 名詞 サ変接続
ヲ 助詞 格助詞 一般
セッケイ 名詞 サ変接続
シ 動詞 自立
テ 助詞 接続助詞
キ 動詞 非自立
タ 助動詞
センジン 名詞 一般
タチ 名詞 接尾 一般
ガ 助詞 格助詞 一般
イル 動詞 自立
。 記号 句点よく考えてみると、自分に日本語の文法知識があまりないので、この分解が妥当なのかを判断できませんが、悪くはないんじゃないでしょうか。むしろ、「してきた、ってこんなに細かく分けるの?」と思いました。
ここで「
サ変接続」名詞とかの情報をうまく使えば面白いのかもしれませんが、面倒なのでうまい利用法が思いつかないので、今回は使いません。
さて、それっぽいデータを得られるようになってきたので、集計する方法を準備します。
集計には、汎用のプログラム言語やExcelでも何を使ってもいいのですが(当初はRubyでHashを使ってやってみていました)、統計処理に特化した「R言語」なるものがあるので、それを使います。MeCabと同様に、自分の場合(macOS 12.6)は、Homebrew からインストールしました。
さて、前述のMeCabの結果のままでは、各行のよみがなが品詞単位で1文字だったり2文字以上だったりするので、(カナの頻度を集計するには)ちょっと扱いにくいのです。集計しやすくするため、よみがなをバラバラにして1文字ずつのよみがなデータをつくります。
Rに触れるのは初めてだったため、一番苦労したのはここの部分です。3
テキストファイル(sample.txt)を読み込んで、望む処理をするプログラムは次のようになりました。
#便利なパッケージを使うための宣言(別途インストールが事前に必要)
require(tidyverse)
# tab区切りのデータの読み込み。dataに結果を代入。
data <- read_tsv("sample.txt",col_name=FALSE) %>%
#column名の設定
rename(よみ=X1,品詞=X2) %>%
#よみがなをlistにしたデータを列に追加しておく。
mutate(yomi_tmp=strsplit(よみ,""))
#よみがながつけられなかったケースで、値にNAを含むときの処理。今思うと必要ないかも。
data$yomi_tmp <- replace(data$yomi_tmp, which(is.na(data$yomi_tmp)), "∎")
#データの行数をnに代入
# tibble 型でなく整数型がほしいので、[[]]で行数を取り出しnに代入
n <- count(data)[[1,1]]
# 読みがなを1文字ずつにしたデータをあらたに作成する処理
# Rならもっとスマートな書き方があってほしいように思うが、現状ではわからず。
# 結果を入れるためのものを用意
t_data <- tibble(よみ=c(""),品詞=c(""))
i <- 1
while(i <= n){
m <- length(data$yomi_tmp[[i]])
j=1
while(j<=m){
chr <- data$yomi_tmp[[i]][[j]]
t_data <- t_data %>%
add_row(よみ=chr, 品詞=data$品詞[i])
j <- j+1
}
i <- i +1
}
#最初の1行は不要なので削除する。
t_data <- t_data[-1,]
#データの表示
print(t_data)実行結果は次の通り。
# A tibble: 20 × 2
よみ 品詞
<chr> <chr>
1 ハ 名詞
2 イ 名詞
3 レ 名詞
4 ツ 名詞
5 ヲ 助詞
6 セ 名詞
7 ッ 名詞
8 ケ 名詞
9 イ 名詞
10 シ 動詞
11 ヨ 動詞
12 ウ 助動詞
13 ト 助詞
14 イ 助詞
15 ウ 助詞
16 モ 名詞
17 サ 名詞
18 モ 助詞
19 イ 動詞
20 ル 動詞欲しかったデータが得られました。
ちなみに、tibbleというのは表のような形式のデータで、上のデータでは20行 × 2列のtibbleであることが表示されています。
ここまでできれば、あとは条件をつけて集計するだけです。
たとえば、dataをよみがなの列のデータで集計するには、次のようにします。
print(data %>%
group_by(よみ) %>%
summarise(出現回数=n()) %>%
arrange(-出現回数))言葉でいうと、dataの「よみ」の列のデータの出現回数を集計して、降順で並び替える処理です。 表示結果は次のようになります。
# A tibble: 18 × 2
よみ 出現回数
<chr> <int>
1 イ 3
2 ン 3
3 シ 2
4 セ 2
5 タ 2
6 。 1
7 ガ 1
8 キ 1
9 ケ 1
10 ジ 1
11 チ 1
12 ッ 1
13 ツ 1
14 テ 1
15 ハ 1
16 ル 1
17 レ 1
18 ヲ 1カナと品詞のペアで集計するときは、group_byの引数を変更します。コードと実行結果はそれぞれ次のようになります。
print(data %>%
group_by(よみ,品詞) %>%
summarise(出現回数=n()) %>%
arrange(-出現回数))# A tibble: 22 × 3
# Groups: よみ [18]
よみ 品詞 出現回数
<chr> <chr> <int>
1 イ 名詞 2
2 セ 名詞 2
3 ン 名詞 2
4 。 記号 1
5 イ 動詞 1
6 ガ 助詞 1
7 キ 動詞 1
8 ケ 名詞 1
9 シ 接頭詞 1
10 シ 動詞 1
# … with 12 more rows
# ℹ Use `print(n = ...)` to see more rowsデータが大量のとき表示が大変なので、明確に指示を与えない限りprint関数は全てを表示しないようになっていて、 最後の2行の英語はそういうことを言ってくれているようです。
連接するカナを考えたいときに、便利な関数があります。lead関数です。
「よみ」と「品詞」というカラムがあるデータの各行について、次の行の内容を持つカラムを追加したデータを作成するコードは下記の通りです。
#2-gram用に、後続するカナと品詞のデータ列をそれぞれ追加したデータをつくる。
ren <- data %>%
mutate(nextchar=lead(よみ)) %>%
mutate(next_lex=lead(品詞))
print(n=30, ren)実行結果を見てみると、確かに次の行の内容が追加されていることが確認できます。最後の行の”NA”というのは、欠損値を表すデータです。文の最後の文字に次はないためです。
# A tibble: 25 × 4
よみ 品詞 次のよみ 次の品詞
<chr> <chr> <chr> <chr>
1 シ 接頭詞 ン 接頭詞
2 ン 接頭詞 ハ 名詞
3 ハ 名詞 イ 名詞
4 イ 名詞 レ 名詞
5 レ 名詞 ツ 名詞
6 ツ 名詞 ヲ 助詞
7 ヲ 助詞 セ 名詞
8 セ 名詞 ッ 名詞
9 ッ 名詞 ケ 名詞
10 ケ 名詞 イ 名詞
11 イ 名詞 シ 動詞
12 シ 動詞 テ 助詞
13 テ 助詞 キ 動詞
14 キ 動詞 タ 助動詞
15 タ 助動詞 セ 名詞
16 セ 名詞 ン 名詞
17 ン 名詞 ジ 名詞
18 ジ 名詞 ン 名詞
19 ン 名詞 タ 名詞
20 タ 名詞 チ 名詞
21 チ 名詞 ガ 助詞
22 ガ 助詞 イ 動詞
23 イ 動詞 ル 動詞
24 ル 動詞 。 記号
25 。 記号 NA NA以上で、準備は整いました。
どんな文章をサンプルにするべきか、それだけでも議論は尽きないところですが、そこはあんまり気にせず、とりあえず青空文庫からデータを取ってきましょう。
寺田寅彦の「科学と文学」にしてみます。このテキストファイルを使ってみます。文字数は2万5千字くらいでしょうか。
ルビありのテキストなので、ルビとルビ前後の記号を取り除く前処理をした方がいいと思いますが、すべての漢字にルビをふってあるわけでもないしそういうことは気にしないことにします。
なお、テキストファイルの文字エンコーディングがShift JISのため、なんとなくUTF-8に変更しておきました。
テキストファイル(kagakuto_bungaku.txt)をMeCabで処理した結果をファイル(kb_parsed.txt)に書き出すには、たとえば次のようにします。(macOSでターミナルを使った場合)
cat kagakuto_bungaku.txt | mecab --unk-format="%M" -E "" -B "" -F "%F\t[7,0]\n" > kb_parsed.txtちなみに、ここで出力されたファイル(kb_parsed.txt)をテキストエディタで開いたところ、「改行コードが混在している」と出たので、変換しておきました。MeCabのデフォルトの文字エンコーディングはEUC-JPといった情報もあり、そのあたりの問題かもしれません。
さて、このサンプルの単純なカナの出現回数Top 10は次のようになりました。
よみ 出現回数
<chr> <int>
1 イ 1916
2 ウ 1782
3 ノ 1626
4 ン 1582
5 シ 1385
6 カ 1130
7 ト 993
8 ル 955
9 ク 932
10 ナ 916「イ」は堂々と1位でした。
2-gramのTop 10は次の通りです。
よみ 次のよみ 出現回数
<chr> <chr> <int>
1 ョ ウ 373
2 デ ア 366
3 ア ル 344
4 ガ ク 271
5 ル 。 268
6 シ ョ 227
7 ブ ン 222
8 モ ノ 222
9 ヨ ウ 212
10 ナ イ 209カナの2-gram出現回数の1位は「ョウ」でした。これもやっぱり強い。
2位と3位の「デア」と「アル」は「である調」の文だからかもしれません。 文体が「ですます調」の場合は、「ス」を含んだものに置き換わってくると思われます。
また、「ガク」が4位に食い込んでくるのは、この文章が「科学と文学」について書かれているからでしょう。
品詞の連接も考えると、そのパターンの数は順序を含めて「品詞の種類×品詞の種類」になるので、どういったパターンに着目すべきか、悩ましいところがあります。
とりあえず、品詞の連接も区別した2-gramはこんな感じです。
# 品詞の連接も区別した2-gram
print(n=10,d %>%
group_by(よみ, 次のよみ,品詞, 次の品詞) %>%
summarise(出現回数=n()) %>%
arrange(-出現回数))
# 実行結果
よみ 次のよみ 品詞 次の品詞 出現回数
<chr> <chr> <chr> <chr> <int>
1 デ ア 助動詞 助動詞 364
2 ョ ウ 名詞 名詞 336
3 ガ ク 名詞 名詞 269
4 ア ル 助動詞 助動詞 252
5 ブ ン 名詞 名詞 220
6 モ ノ 名詞 名詞 214
7 ヨ ウ 名詞 名詞 203
8 シ ョ 名詞 名詞 199
9 ル 。 助動詞 記号 187
10 コ ト 名詞 名詞 165品詞の連接も区別している分、もっとバラけるかとも思いましたが、カナだけの2-gramと似た感じです。 そもそも全体から見れば、名詞の割合が多いので「名詞」の中に含まれる2-gramが多いですね。
この結果から「名詞 名詞」というパターンを除くとどうなるか、やってみます。 filter関数を使います。
# 2-gramのデータから品詞が「名詞 名詞」のパターンをfilterで除く
print(n=10,d %>%
group_by(よみ, 次のよみ,品詞, 次の品詞) %>%
filter(品詞!="名詞" & 次の品詞!="名詞") %>%
summarise(出現回数=n()) %>%
arrange(-出現回数))
# 実行結果
よみ 次のよみ 品詞 次の品詞 出現回数
<chr> <chr> <chr> <chr> <int>
1 デ ア 助動詞 助動詞 364
2 ア ル 助動詞 助動詞 252
3 ル 。 助動詞 記号 187
4 ナ イ 助動詞 助動詞 130
5 ス ル 動詞 動詞 122
6 。 記号 記号 95
7 レ ル 動詞 動詞 92
8 ソ ノ 連体詞 連体詞 87
9 ト イ 助詞 助詞 83
10 シ テ 動詞 助詞 81「ナイ」「スル」が上位に上がってきました。
ここでふと、「ない」って形容詞じゃないのかな? と気になったので、品詞が「形容詞 形容詞」というパターンだけを抽出してみます。
# 2-gramのデータから品詞が「形容詞 形容詞」のパターンをfilterで除く
print(n=10,d %>%
group_by(よみ, 次のよみ,品詞, 次の品詞) %>%
filter(品詞=="形容詞" & 次の品詞=="形容詞") %>%
summarise(出現回数=n()) %>%
arrange(-出現回数))
# 実行結果
よみ 次のよみ 品詞 次の品詞 出現回数
<chr> <chr> <chr> <chr> <int>
1 ナ イ 形容詞 形容詞 54
2 ナ ク 形容詞 形容詞 26
3 シ イ 形容詞 形容詞 24
4 オ オ 形容詞 形容詞 15
5 ラ シ 形容詞 形容詞 13
6 オ イ 形容詞 形容詞 11
7 シ ク 形容詞 形容詞 11
8 タ ラ 形容詞 形容詞 11
9 ア タ 形容詞 形容詞 10
10 ク ナ 形容詞 形容詞 9出現回数がかなり少なくなってしまいましたが、「形容詞 形容詞」のケースでは「ナイ」が多いようでした。 「ナク」は多分「ナイ」の活用形ですが、こういう部分はもっと細かい品詞情報を拾って、活用形全体をグルーピングしたりできるといいのかもしれません。
品詞の連接するパターンが細かくなりすぎるのも考えものです。もう少しゆるやかなグループ分けとして、形容詞、動詞、助詞、助動詞、副詞、連体詞、接続詞、接頭詞をひとくくりにして集計してみるとどうでしょうか。(とはいえ、まとめすぎるのもどうなのか、と思いつつ。)
#形容詞、動詞、助詞、助動詞等をまとめて集計する
print(n=10,d %>%
filter(品詞=="形容詞"|品詞=="動詞"|品詞=="助詞"|品詞=="助動詞"|品詞=="副詞"|品詞=="連体詞"|品詞=="接続詞"|品詞=="接頭詞") %>%
filter(次の品詞=="形容詞"|次の品詞=="動詞"|次の品詞=="助詞"|次の品詞=="助動詞"|次の品詞=="副詞"|次の品詞=="連体詞"|次の品詞=="接続詞"|次の品詞=="接頭詞") %>%
group_by(よみ, 次のよみ) %>%
summarise(出現回数=n()) %>%
arrange(-出現回数))
# 実行結果
よみ 次のよみ 出現回数
<chr> <chr> <int>
1 デ ア 366
2 ア ル 343
3 シ テ 196
4 ナ イ 187
5 イ ウ 163
6 ス ル 138
7 ッ テ 134
8 ソ ウ 110
9 ト イ 97
10 ッ タ 95とまあこんな感じで、集計の仕方には色々と工夫に余地があります。
ぜんぜんまとまってないですが(笑)、きりがないのでひとまずここで区切ります。
前述の通り、この集計のやり方は、形態素解析エンジンと辞書、その品詞体系に依存しています。 解析の精度や、品詞体系の適切さには限度があると思います。
あとはサンプルですね。内容や文体によって変わるのでもっと多様なサンプルでやるとか。
品詞のグループ分けも、「活用のある自立語」のような分け方がいいのか、とか。
そういえば冒頭に述べた、「い」はどんな役割で、どのくらい使われているのか、ということについて、「科学と文学」の「い」の品詞別使用ランキングはこうでした。
# イの品詞別使用ranking top 10
print(d %>%
group_by(よみ, 品詞) %>%
filter(よみ=="イ") %>%
summarise(出現回数=n()) %>%
arrange(-出現回数))
# 実行結果
よみ 品詞 出現回数
<chr> <chr> <int>
1 イ 名詞 1093
2 イ 動詞 196
3 イ 形容詞 137
4 イ 助動詞 135
5 イ 助詞 117
6 イ 連体詞 106
7 イ 副詞 82
8 イ 接続詞 26
9 イ 接頭詞 18
10 イ 記号 6「記号 6」ってなんだ? と思いつつ、名詞の頻度が高かったです。 一方、「の」の品詞別使用ランキングはこうでした。
よみ 品詞 出現回数
<chr> <chr> <int>
1 ノ 助詞 1052
2 ノ 名詞 426
3 ノ 連体詞 129
4 ノ 副詞 12
5 ノ 動詞 5
6 ノ 形容詞 2おまけ。
#記号とその前の記号でないものの並びをカウントする
print(n=10,d %>%
filter(品詞!="記号") %>%
filter(次の品詞=="記号") %>%
group_by(よみ, 次のよみ) %>%
summarise(出現回数=n()) %>%
arrange(-出現回数))
# 実行結果
よみ 次のよみ 出現回数
<chr> <chr> <int>
1 ル 。 268
2 テ 、 83
3 ハ 、 80
4 イ 。 52
5 ガ 、 51
6 モ 、 50
7 ノ 「 42
8 ウ 。 39
9 タ 。 34
10 ニ 、 34